Inhalte
- Aufbau und Konzeption der Website
- Die einzelnen Zugangsebenen der PPM/MPS-Website
- Die Eingabeoberflächen für PPM/MPS-spezifische Datenmodelle
- Dateneingabe
- Die Präsentation der PPM/MPS-Datenkategorien im Front-End des MPS-Repository
- Information-Retrieval im PPM/PMS-Webauftritt
- Datenfreigabe: User Level des MPS-Repository
- Datenimport und -export
- Text als PDF (Originalfassung):
Aufbau und Konzeption der Website
Technische Einführung
Das Konzept des PPM/MPS sieht vor, dass ein Großteil des wissenschaftlichen Arbeits- und Publikationsprozesses online durchgeführt wird. Um den heterogenen Forschungsanforderungen und einem breit gestreuten Publikum gerecht werden zu können, wurde als Softwaregrundlage für den Internetauftritt die Open Source Software WordPress und als Datenbanksystem eine relationale SQL-Datenbank gewählt.1 Als Zielgruppe für die Webanwendung werden folgende Personengruppen definiert: Forschende aller Altersgruppen aus unterschiedlichen Disziplinen, Studierende (selbsttätig oder unter Anleitung) und mittelfristig natürlich auch die interessierte Öffentlichkeit. Das stellt bestimmte Anforderungen an eine Online-Software, die im Rahmen eines selbstfinanzierten Projektes eingesetzt wird: Unabdingbar ist ein stabiles System mit geringem Wartungsaufwand, das sich durch leichte Erweiterbarkeit und durch ein automatisiertes Update-System für die laufende Wartung und Aktualisierung auszeichnet. Es muss leicht für individuelle Bedürfnisse adaptierbar sein. Die finanzielle Lage des Projektes und die entsprechende ideelle Haltung der Seitenbetreiber verlangt nach einer Open Source Software. Diese muss offene Schnittstellen unterstützen und mit Standard CMS Funktionalität ausgestattet sein. Das WordPress Softwarepaket entspricht diesen Anforderungen und stellt darüber hinaus weitere Features zur Verfügung.
Die Basisausstattung überzeugt vor allem mit einem sehr guten Security Record. Das Datenkonzept der Software bietet die Möglichkeit zur Verwaltung von strukturierten wie unstrukturierten Inhalten und die Möglichkeit zur Verwaltung von Mediendaten. Die Installation multipler Instanzen ist ebenfalls vorgesehen. Das Benutzersystem baut auf einer rollenbasierten Rechtevergabe auf. Für die Software besteht eine umfassende Erweiterbarkeit über Plug-Ins (derzeit gibt es über 33.000), diese und die Software selbst sind GPL lizensiert. Da WordPress zur Zeit als das meistbenutzte CMS gilt [vgl. Wikipedia (09.09.2014)], wird die Entwicklung stetig durch eine hochaktive Entwickler-Community vorangetrieben. Zusätzliche Features machen diese Software noch attraktiver: die suchmaschinenoptimierte Inhaltsausgabe, das flexible Template-System, die hohe Performance und die leichte Skalierbarkeit, der native Support für strukturierte und unstrukturierte Taxonomien, die native Integration von XML- und JSON-Schnittstellen, bereits implementierte Kommunikationsmöglichkeiten (z. B. Kommentare) und deren unproblematische Erweiterbarkeit, sowie die automatische Vernetzung von referenzierten Seiten via Trackbacks. Das CMS bietet außerdem die Möglichkeit, mittels filters und actions2 beinahe alle Bereiche des Basissystems an individuelle Bedürfnisse anzupassen. Für die Umsetzung der für das PPM/MPS formulierten Forschungsziele kann auf Softwareebene u. a. auf Custom Post Types, projektspezifische und generische Metadaten, Indexlisten, relationale Abhängigkeiten, die Integration von komplexen Suchanfragen und einer umfassenden Volltextsuche auf Basis von Apache Lucene sowie die Möglichkeit der optischen Aufbereitung von Datenvernetzungen, um inhaltliche Zusammenhänge zu veranschaulichen,3 zurückgegriffen werden.
Das konzeptionelle Herzstück der PPM/MPS Online-Software ist die Verknüpfung der CMS-Funktionalität mit den benutzergenerierten Daten. WordPress bietet nativ nur zwei Arten von Datentypen: Posts (unstrukturiert) und Pages (auch: ‚Seiten‛; hierarchisch strukturiert).4 Ein generisches Taxonomiesystem und allgemeine Metadaten ergänzen diese softwareseitig vorgegebene Struktur. Mit WordPress 3.0 wurden zudem Custom Post Types eingeführt, die es ermöglichen, die Software um eigene, projektspezifische Datentypen zu erweitern, diese können entweder unstrukturiert oder hierarchisch strukturiert implementiert werden. Über ein projektspezifisches Plug-In werden zusätzliche Methoden implementiert, die Custom Post Types um beliebige Metadaten erweitern. Spezifische actions ermöglichen es, diese Daten in CMS-externen Strukturen zu verspeichern. Das Ergebnis ist ein individuelles Eingabesystem im Stil der Grundsoftware, das aber ausreichend Flexibilität bietet, um Standard-Plug-Ins der Online-Software für die individuellen Daten zu verwenden. Diese Taxonomien und ihre Verarbeitungsroutinen müssen selbstverständlich individuell programmiert werden. Trotz dieses Mehraufwandes überwiegen die Vorteile dieses Lösungsansatzes, deren größter der Umstand ist, dass keine Änderungen am Kernsystem notwendig sind und damit immer ein stabiler Webauftritt gewährleistet ist.
Die einzelnen Zugangsebenen der PPM/MPS-Website
Die Softwarebasis des PPM/MPS ist also eine WordPress-Multisite-Installation, die eine zentrale Verwaltung der Softwareelemente und der Benutzer für alle Unterseiten bietet und es damit ermöglicht, mehrere virtuelle Webseiten mit einer WordPress-Installationen in Form eines Informationsnetzwerkes zu betreiben.5 Diese virtuellen Seiten sind für das PPM/MPS der MPS-Blog und das MPS-Repository. Die Webpräsenz, die für diesen Zweck aufgebaut wurde, ist ein komplexes Gebilde mit mehreren Zugangsebenen, die je nach Betrachtungsweise auf unterschiedlichste Art in verschiedene Sinneinheiten untergliedert werden können: Aus softwaretechnischer Sicht gibt es fünf unterschiedliche Ebenen. Vom arbeitstechnischen Standpunkt erhält man eine Dreiteilung des Internetauftritts. Gliedert man die Zugangsebenen zielgruppenorientiert, kann man zwei Bereiche unterscheiden. Die fünf Ebenen umfassen die Verwaltungsoberfläche der Multisite-Installation6, das Front-End7 der Blogoberfläche, das Back-End8 der Blog-Oberfläche, das Front-End des Repositorys9 und das Back-End des Repositorys.10 Diese Bereiche kann man in drei arbeitstechnisch relevante Zugangsebenen zusammenfassen: die Verwaltungsoberfläche der Multisite-Installation, die Präsentationsebene, die sich aus Front-End der Blogoberfläche, Back-End der Blog-Oberfläche, Front-End des Repositorys und Teile des Back-End des Repositorys zusammensetzt und den Verwaltungsbereich der Datensammlung: Das sind Teile des Back-Ends des Repositorys. Eine zielgruppenorientierte Gliederung unterscheidet nur zwischen jenen Bereichen der Website, die zur Datenpräsentation (Front-End) und Datengenerierung (Back-End) dienen; diese decken sich aufgrund von rudimentären Dateneingabemöglichkeiten im Front-End11 aber nicht konsequent mit den von der Software vorgegebenen Ebenen.
Die Verwaltungsoberfäche der Multisite-Installation bietet dem Site-Administrator, welcher ausschließlich Zugang zu diesem Bereich hat, übergreifende organisatorische Möglichkeiten, wie z. B. die verwaltungstechnische Wartung einzelner Webseiten (Basisinformation, Benutzer, grafische Darstellung, Grundeinstellungen), die übergreifende Organisation von Benutzern des Netzwerkes sowie der Benutzer der Einzelseiten, die Verwaltung der vorhandenen grafischen Oberflächen (Themes),12 die Installation, Aktivierung sowie Konfiguration der Softwareerweiterungen (Plug-Ins), das Setzen allgemeiner Einstellungen und das Ausführen seitenübergreifende Aktualisierungen.
Das Front-End der Blogoberfläche ist der Zugang zu allen Informationen, die für eine science-to-public-Dissemination aufbereitet worden sind: Konkret werden hier neu eingepflegte Datenpakete und softwaretechnische Neuerungen der Website vorgestellt; es gibt Berichte zu relevanten Neuerscheinungen und außerdem werden projektrelevante Neuigkeiten, wie z. B. die Präsentation der Website im Rahmen von Tagungen, publiziert. Der Zugang zu den Inhalten ist möglich über die chronologisch sortierte Blog-Roll oder thematisch vorselektiert über einzelne Kategorien, die im Seitenmenü aufgelistet sind und denen Posts zugewiesen sind, oder über vereinzelte Stichwörter, die für Posts vergeben worden sind. Als weitere Navigationsmöglichkeiten gibt es im Hauptmenü einen Hyperlink („Repository‟), um in das MPS-Repository zu wechseln; man kann hier auf eine kurze Projektbeschreibung („Über …‟) und auf organisatorische Seiten zugreifen: Es gibt die Möglichkeit, mit den Seitenbetreibenden Kontakt („Kontakt‟) aufzunehmen sowie die Allgemeinen Geschäftsbedingungen („AGB‟), die alle rechtlichen Aspekte des Internetauftrittes regeln, einzusehen; noch nicht registrierte Benutzer können sich hier registrieren („Registrieren‟).
Das Back-End der Blogoberfläche bietet alle Funktionen, die eine zeitgemäße Blogging-Software bieten kann. Neben diversen organisatorischen Einstellungsmöglichkeiten (erreichbar über die folgenden Hyperlinks im Seitenmenü: „Formular‟, „Design‟, „Plugins‟, „Benutzer‟, „Werkzeuge‟, „Einstellungen‟, „Redirect Options‟) kann hier der Content der Blogoberfläche verwaltet werden: Unter der Rubrik ‚Beiträge‛ greift man auf die Posts und unter der Rubrik ‚Seiten‛ auf Pages zu; jeder einzelne dieser Einträge kann nach erfolgter Publikation jederzeit inhaltlich geändert bzw. überarbeitet werden, gleichzeitig sind auch verwaltungstechnische Änderungen (Publikationsdatum, Autor, SEO Daten etc.) möglich.13 Die Hyperlinks „Medien‟ und „Links‟ führen zur Verwaltungsoberfläche für diese Content-Elemente. Als Mediendaten gelten in diesem Zusammenhang eigentlich jegliche Art von Dateien, aber natürlich ganz speziell alle Bild-, Video- und Musikdateien, die in ihren Anzeige- und Bearbeitungseigenschaften von WordPress nativ stärker unterstützt werden (z. B. durch Bildbearbeitungsmöglichkeiten). Medien, die hier verwaltet werden, können z. B. in Posts oder Pages eingebaut werden. Unter der Rubrik ‚Kommentare‛ können allfällige Benutzerrückmeldungen, die mittels der Kommentarfunktion zu einzelnen Posts übermittelt wurden, moderiert werden.
Das Front-End des MPS-Repositorys ermöglicht den lesenden Zugang zu allen im Rahmen des PPM/MPS gesammelten Daten. Als Einstieg in die den Forschungen zugrundeliegende Thematik wird auf dieser Seite als statische Information eine kurze Projektskizze angeboten. Das Menü im Kopfbereich der Seite beinhaltet die Hyperlinks zu den einzelnen Datenkategorien, die als Custom Post Types in die WordPress Installation implementiert wurden: den „Pflanzennamen‟, “Texte‟, bildlichen Pflanzendarstellungen („Darstellungen‟), „Handschriften‟, „Druckwerken“. Das Menü im Fußbereich der Website enthält Links zu Einzelseiten mit organisatorischem Inhalt: Die Seite „Inhalt‟ bietet einen gerafften Überblick über alle Daten, die zur Zeit im Rahmen der Webpräsenz zugänglich sind. „Benutzerlevel‟ öffnet eine Seite, die das Modell der unterschiedlichen Zugangsebenen zum Inhalt der Webpräsenz im Detail aufschlüsselt. Die Seite „Mitarbeitende“ enthält eine Liste mit Kurzinformationen zu jenen Personen, die maßgeblich am Inhalt des PPM/MPS und der Präsentation desselben mitgewirkt haben.
Der Hyperlink „Kontakt‟ öffnet ein Kontaktformular. Weitere Links führen zu den Allgemeinen Geschäftsbedingungen („AGB‟) und zum Registrierungsformular („Registrieren‟), mit dem man sich als Benutzer der Website eintragen kann. Durch Klicken auf das Lupensymbol in der rechten oberen Ecke gelangt man zu den Suchformularen, die zur Suche in den Forschungsdaten des MPS-Repositorys eingerichtet sind. Die Bilder rechts auf der Startseite stellen eine Auswahl an Fotografien historischer Pflanzenabbildungen und Fotos von Pflanzen, die im Mittelalter bekannt waren, dar: Diese dienen nicht nur als grafischer Eyecatcher, sondern sie sind maßgeblich ein Mittel zur Bewusstseinsbildung (science-to-public) in Portal-externen Bereichen des Internet. Im konkreten Fall passiert das im Rahmen der Foto-Community Flickr, wo mithilfe einer Flickr-Group der Thematik entsprechende Abbildungen gesammelt werden.14
Das Back-End des MPS-Repositorys ist das Datenverwaltungszentrum des PPM/PMPS. Man hat hier über das Seitenmenü nicht nur Zugriff auf die WordPress-nativen Organisationselemente (Hyperlinks: „Formular‟, „Design‟, „Plugins‟, „Benutzer‟, „Werkzeuge‟, „Einstellungen‟, „Eigene Felder‟, „Custom Post Types‟, „Galerie‟, „Redirect Options‟) und Content-Bearbeitungsmodule (Hyperlinks: „Beiträge‟, „Medien‟, „Links‟, „Seiten‟, „Kommentare‟ etc.), sondern auch auf die PPM/MPS-spezifischen Datenmodelle: „Druckwerke‟ öffnet die projektinterne Literaturverwaltung; der Bereich ‚Indexsprachen‛ dient zur Verwaltung der einführenden Informationen zu den Sprachen der Pflanzennamenindices. „Pflanzennamen‟ öffnet die Bearbeitungsoberfläche der Pflanzennamensammlung, „Handschriften‟ jene für die Sammlung der Handschriften. Der Hyperlink „Texte‟ führt zur Indexseite der projektinternen Quellentextsammlung.
Die Indexseiten der Datenkategorien des PPM/MPS im Back-End des MPS-Repositorys
Da für WordPress als open source Content Management System Benutzerfreundlichkeit einen hohen Stellenwert hat, sind die Oberflächen im Back-End durchgehend nach dem gleichen Muster aufgebaut, sodass es für eine einführende Darstellung ausreicht, exemplarisch eine einzelne Seite im Detail vorzustellen. Die Indexseiten der einzelnen Datenbereiche werden an jener der Pflanzennamen erläutert:
Eine Indexseite ist die erste Zugangsebene zu jeder Datenrubrik15 und zeigt bei Seitenaufruf eine tabellarische Auflistung aller Datensätze sortiert nach Zeitpunkt der Erstellung des Datensatzes an. Die Daten können aber auch in alphabetischer Reihenfolge nach Datensatztitel („Titel‟) oder nach Anzahl der Kommentare („Sprechblasen-Icon‟), die ein Datensatz hat, aufsteigend oder absteigend gelistet werden, indem die einzelnen Hyperlinks angeklickt werden. Ein Suchfeld bietet die Möglichkeit, die Datensatztitel zu durchsuchen. Die Liste der Datensätze wird abhängig vom Suchbegriff entsprechend eingeschränkt. Eine Listenseite umfasst standardisiert 20 Datensätze, wobei man hier entweder alle vorhandenen Datensätze anzeigen lassen kann oder nur jene, die bereits publiziert wurden.16 Über eine Pfeilnavigation oder durch die Eingabe von Zahlenwerten kann man durch die vorhandenen Seiten navigieren. Datensätze können, wenn in der Listenansicht das Kontrollkästchen vor einem Datensatz (Mehrfachauswahl für die gleichzeitige Bearbeitung mehrere Datensätze ist möglich) aktiviert ist, zum Bearbeiten geöffnet oder in den Papierkorb verschoben werden.
Navigiert man mit dem Cursor über die Datensatztitel, werden jeweils zusätzliche Bearbeitungselemente angezeigt: ‚Bearbeiten‛ öffnet die Datenblattansicht; ‚QuickEdit‛ öffnet eine eingeschränkte Bearbeitungsansicht, in der Titelinformationen, Publikationsdatum, Datensicherheitsinformationen, Schlagwörter und der Veröffentlichungsstatus geändert werden können. Ein Klick auf den Hyperlink „Papierkorb‟ verschiebt den Datensatz in den Papierkorb; „Anschauen‟ öffnet die Datensatzansicht im Front-End des MPS-Repository.
Die Eingabeoberflächen der WordPress Datenkategorien: Allgemeine Elemente
Die Datenblätter der einzelnen Datensatztypen sind nach den Vorgaben von WordPress analog aufgebaut und weisen immer bestimmte vordefinierte Felder auf: Standardwerte, die systemintern für alle Datensätze vergeben werden, sind ein inhaltlich frei zu definierender Titel* und ein allgemeines, für den gesamten Datensatz gültiges Textfeld, das für jegliche Art von Freitext genutzt werden kann.17 Zusätzlich gibt es die Möglichkeit, allgemeine Notizen oder spezifische Diskussionen (auch zwischen mehreren Benutzern), die Bezug zum gesamten Datensatz haben, über vom System vorgesehene Kommentarroutinen zu verspeichern. Als Möglichkeit, rudimentäre Metadaten zu akkumulieren, kann man in WordPress einzelne Datensätze in Kategorien einteilen und zusätzlich mit Schlagworten (Tags) beschreiben. In den projektinternen Datenmodellen ist vorgesehen, dass zusätzlich eine beliebige Anzahl an Datenfeldern für Primär- und Metadaten implementiert werden kann. In diesem Rahmen werden für einzelne Datenfelder, für die ein erhöhter Kommentarbedarf angenommen werden kann, wiederum eigene Kommentarfelder vergeben. Die Publikationsdaten für einen Datensatz (Veröffentlichungsstatus, Sichtbarkeitsstatus, Publikationsdatum) werden vom System immer automatisiert verspeichert, können aber, wie auch die Informationen zum Datensatzautor, nachträglich geändert werden.
Die Eingabeoberflächen für PPM/MPS-spezifische Datenmodelle
Druckwerke
Für die Beschreibung der gedruckten Literatur werden alle für ein bibliografisch vollständiges Titelzitat relevanten Daten mithilfe eines Custom Post Type verspeichert: Publikationstyp*18, Autor*, Art der Literatur (primär vs. sekundär), Herausgeber, Titel*, Untertitel, qualitative und quantitative Angaben, Verlag, Verlagsort, Reihentitel, Reihennummer, Entstehungszeit, Publikationsjahr, Seiten- oder Spaltenumfang, Zeitschriftentitel, Jahrgang, Heftnummer, Universitätsort, Art einer Qualifikationsschrift (Bachelorarbeit, Diplomarbeit, Masterarbeit, Dissertation, Habilitationsschrift), Bibliothek, Signatur, Hyperlink, ISBN, ISBN-13, Kommentar. Der Datensatztitel ist die für das Werk vergebene Sigle.19
Ausgehend von diesen Eingabefeldern können verschiedene Typen von Titelzitaten ausgegeben werden, die allerdings im Zuge der Dateneingabe spezifiziert werden müssen: Monografie, Monografie mit Herausgeber, Aufsatz in einem Sammelband, Aufsatz in einer Zeitschrift, Qualifikationsschrift oder Internet-Quelle. Zusätzlich kann für die einzelnen Datensätze angegeben werden, ob es sich bei den beschriebenen Werken um Primär- oder Sekundärliteratur handelt. Mit der Angabe zur Entstehungszeit eines Werkes können Abweichungen zum Publikationsdatum berücksichtig werden, was vor allem von Bedeutung ist, wenn es sich um Editionen historischer Texte oder Reprint-Drucke handelt. Für interne und organisatorische Zwecke kann außerdem die Quelle erhoben werden, über welche die jeweilige Literatur bezogen wurde: Diese Daten umfassen Angaben zu Bibliothek, Signatur, ISBN oder ISBN-13 oder einen Hyperlink.
Zur Zeit ist es möglich, Bücher mit Handschriften zu verknüpfen; eine Ausweitung der Verknüpfung auf Pflanzennamen und Quellentexte scheint in Bezug auf das Einpflegen von historischen Glossendaten sinnvoll.
Datenbankfeld – Beschreibung
Titel: Sigle oder Kurztitel (Autor: Titel) des Werkes
Type: Hier kann die Publikationsart eines Druckwerkes eingegeben werden: Buch, Buch mit Herausgeber, Teil eines Buches (z. B. ein Kapitel, ein Aufsatz in einer Sammlung), Zeitschriften- oder Jahrbuchaufsatz, Qualifikationsarbeit, Webseite
Author: Namen des Autors, der Autoren
Literature-Type: Hier wird festgelegt, ob es sich um Primär- (Primary) oder Sekundärliteratur (Secondary) handelt.
Editor: Namen des Herausgebers, der Herausgeber
Title: Vollständiger Titel des Werkes
Subtitel: Vollständiger Untertitel des Werkes
Appendizes: Quantitative und qualitative Angaben: Bandangaben, Angaben zu möglicher Überarbeitung, Übersetzung, Nachdruck
Publisher: Verlagsname
City: Publikationsort
Series: Reihentitel
Volume in Series: Reihennummer
Date of Origin: Entstehungszeit eines Werkes, wenn es sich z.B. um eine Edition oder um einen Nachdruck handelt.
Year: Publikationsjahr
Page: Seitenumfang einer unselbstständigen Publikation
Journal: Zeitschriften- oder Jahrbuchtitel
Issue: Jahrgang
Volume: Heftnummer
University: Universitätsort einer Qualifikationsschrift
Degree: Art einer Qualifikationsschrift: Habilitationsschrift, Dissertation, Diplomarbeit, Masterarbeit, Bachelorarbeit
Library: Name der Bibliothek, an der ein Druckwerk vorhanden ist / entlehnt wurde
Signature: Bibliothekssignatur
Hyperlink: Url einer Website
ISBN: Internationale Standardbuchnummer
ISBN-13: Neue dreizehnstellige Internationale Standardbuchnummer
Comment: Hier ist Raum für jegliche Art von Kommentar zum Druckwerk: Das kann eine persönliche Rezension, ein Link zu einer Rezension oder auch ein Link zu vertiefenden Informationen (Inhaltsverzeichnis etc.) sein.
Bücher Tags: Hier können individuelle Schlagworte für Druckwerke vergeben werden.
Indexsprachen
Die hier verspeicherten Informationen zu den einzelnen Sprachstufen werden im Front-End als Informationsgrundlage zur temporalen und lokalen Verortung der Pflanzennamenindices und einzelner Pflanzennamen verwendet. Das Titelfeld* beinhaltet die neuhochdeutsche Bezeichnung der jeweiligen Sprachstufe. Das Textfeld* ist für einen Beschreibungstext vorgesehen, der u. a. weiterführende Links zu externen ausführlichen Beschreibung anbietet.20 Außerdem werden hier Kurzangaben zur historischen Erstreckung der Sprachperiode und die korrekte grammatikalische Form des Adjektivs zur Bezeichnung der Sprachstufe im Singular und im Plural aufgezeichnet, um damit die Präsentation der Daten im MPS-Front-End zu unterstützen. Erstere Daten werden z. B. als Kurzinformation bei der Anzeige der parallelen Sprachstufen von vernetzten Pflanzennamen unterstützt; die Adjektive werden gebraucht, um einzelnen bzw. mehreren Pflanzennamenbelege grammatikalisch korrekt zu betiteln.21
Datenbankfeld - Beschreibung
Titel: Bezeichnung der Sprache
Post-Text: Hier wird ein kurzer, die Sprachstufe aber möglichst umfassend beschreibender Text eingetragen.
Zeit: Möglichst präzieser Zeitraum, in dem die Sprache gesprochen wurde / wird.
Singular: Adjektivische Bezeichnung der Sprache im Nominativ Singular
Plural: Adjektivische Bezeichnung der Sprache im Nominativ Plural
Pflanzennamen
Ein Pflanzenname wird primär über seine Zuordnung zur jeweiligen Sprachstufe* beschrieben. Eine Angabe der Sprachstufe ist damit obligatorisch, da ein Name ohne Zuordnung zu einer Sprachstufe nicht nur dem Datenmodell widersprechen, sondern auch aus dem vorgegebenen Raster der Datenpräsentation fallen würde. Die Sprachstufe eines Pflanzennamens kann gesondert kommentiert werden, prototypische Daten für dieses Feld wären z. B. Notizen zum Identifikationsprozess oder zur historischen Quelle. Pflanzennamen werden aber auch durch ihre Relation zu anderen Pflanzennamen beschrieben. Diese Datenrelation ist fakultativ und kann auf unterschiedliche Weise interpretiert werden: So kann z. B. eine fehlende Verknüpfungen zu einem neuhochdeutschen Pflanzennamen darauf hinweisen, dass dieser Name (noch) nicht verknüpft oder überhaupt nicht identifiziert ist.22 Der Status zur Identifikation eines Pflanzennamens kann zwei Quellen entnommen werden: Einerseits werden Informationen zum Bearbeitungsstand von Pflanzennamenindices auf der zusammenfassenden Inhaltsübersicht des MPS-Repositorys vermerkt, andererseits indiziert das Vorhandensein einer Pflanzenmonografie, dass ein Pflanzenname vollständig bearbeitet wurde. Mehrfachzuweisungen hingegen zeigen, dass eine Identifikation nicht sicher durchgeführt werden kann, und signalisieren – abhängig von den verknüpften Sprachen und Sprachstufen – heteronyme oder synonyme Abhängigkeiten. Pflanzennamen können außerdem mit einzelnen Quellentexten verknüpft werden, sodass jeder Pflanzenname eine eigene Übersicht an Belegstellen bietet.
Der für jeden einzelnen Datensatz verpflichtend zu vergebene Titel* ist immer der Pflanzenname selbst. Ein Textfeld ist in langfristiger Planung für den Text einer Pflanzenmonografie reserviert und das Kommentarfeld des Datensatzes ist für Arbeitsnotizen vorgesehen, die damit öffentlich zugänglich werden.
Datenbankfeld - Beschreibung
Titel: Hier steht der historische Pflanzenname.
Post-Text: Hierher kommt jener Teil der Pflanzenmonografie, der für diese Sprachstufe relevant ist.
Relationen: Hier kann ein Pflanzenname mit verwandten Pflanzennamen verknüpft werden.
Vorkommen: Hier kann ein Pflanzenname mit Quellentexten verknüpft werden.
Entry-Type: Hier wird mithilfe des ISO-Codes die Zuweisung zu einer Sprachstufe angegeben.
Entry-Type Comment: Raum für beliebigen Kommentar zur Sprachzuweisung: Das können z. B. Informationen zur Identifikation sein
Titelform: Das ist eine vom System vergebener Wert.
Schlagwörter: Hier können individuelle Schlagwort für Pflanzennamen vergeben werden.
Handschriften
Zentrale Information bei der Erhebung von Handschriften ist die Signatur* (Titelfeld), die wesentliche Aussagen über den Standort und teilweise auch über die Art der Quelle mitträgt: Die Signatur setzt sich dabei aus Bibliotheksort, Bibliotheksnamen und der Bezeichnung und Nummer eines Codex zusammen. Eine Trennung dieser Informationen in einzelne Datenfelder wird vorerst nicht vorgenommen. Alle weiteren Felder eines Datensatzes beinhalten fakultative Angaben, so z. B. zu Bestand (verweist mit der jeweiligen projektinternen Sigle auf die Edition, der die Texte der Datenbank entnommen worden sind), Edition* (Dieses Feld enthält das Titelzitat der Edition.), Bearbeitungsstand (Das ist eine interne Information im Rahmen des PPM/MPS.), Referenzen zu externen bibliografischen Sammlungen (Nr. Kranich, Nr. Lambert), Sigle (im Rahmen des PPM/MPS), Entstehungszeit, Schreibdialekt, Entstehungsort, Anzahl der Rezepte, Art der Rezepte, Beschreibung der Handschrift, Inhalte der Handschrift.23 Handschriften sind mit Büchern und mit Quellentexten verknüpft.
Datenbankfeld - Beschreibung
Titel: Der Titel entspricht der Handschriftensigle.
Bestand: Dieses Feld beinhaltet die Information zu der den Datenbankeinträgen zugrundeliegenden Edition des Handschriftentextes. Diese wird in Form einer Kurzsigle (Autorenfamilienname Publikationsjahr) verspeichert.
Edition: Titelzitate der verfügbaren Editionen, chronologisch geordnet.
In Rezept-DB: Kurzinfo, ob die relevanten Quellentexte der Handschrift in der Datenbank verspeichert sind.
Signatur: Handschriftensignatur
Nr. Kranich Regens: Interne Referenznummer
Nr. Lambert: Externe Referenznummer nach der Sammlung von Handschriften, die kulinarische Rezepte beinhalten von Constance Hieatt.
Sprache: Schreibsprache der Handschrift
Sigle: Sigle der Kochrezepttextsammlung nach Marianne Honold
Entstehungszeit: Entstehungszeit der Handschrift
Dialekt: Schreibsprache der Handschrift
Entstehungsort: Entstehungsort der Handschrift
Rezeptanzahl: Rezeptanzahl der Kochrezepttextsammlung
Rezeptart: Übersicht der Rezepte einer Kochrezepttextsammlung nach inhaltlichen Aspekten (Kochrezept, medizinisches Rezept etc.)
Beschreibung: Kodikologische Beschreibung der Handschrift
Inhalt: Beschreibung des Inhaltes einer Handschrift
Texte
Bei Quellentexten setzt sich der Inhalt des Titelfeldes aus einer kurzen, frei wählbaren, aber prägnanten neuhochdeutschen Bezeichnung des Textes24 und der Handschriftensigle als Verweis auf die Quelle zusammen. Belegstellen haben einige wenige verpflichtende Metadatenfelder: Sie müssen einer historischen Quelle (Manuscript*, Druck) zugeordnet sein. Diese ist wohl in den meisten Fällen25 über eine Edition erschlossen. Durch die Verknüpfung des Datensatzes mit einem Manuscript wird der Text automatisiert der damit verknüpften, aktuellsten Edition des Quellentextes zugeordnet; Angaben im Feld Handschrift werden nur dann gesetzt, wenn ein Manuscript mehrere Kochrezepttextsammlungen beinhaltet (z. B. Heidelberg, Universitätsbibliothek, cpg 551). Diese Verknüpfungen werden mit der verpflichtenden Angabe von Referenzdaten ergänzt: Das müssen bei Rezepttexten die jeweilige Rezeptnummer der Edition*26 und/oder die Seiten- oder Folioangaben*27 der historischen Quellen sein, damit für alle Quellentypen ein exakter Referenzpunkt vorhanden ist. Diese Informationen reichen in der Regel aus, um die Belegtexte in den unterschiedlichen Quellenwerken – sowohl in der Edition als auch in der Handschrift – entsprechend bibliografisch und für eine problemlose Wiederauffindbarkeit zu verorten. Alle Datensätze erhalten eine neuhochdeutsche Bezeichnung*, welche die historische Quelle möglichst prägnant beschreibt; dieser Name ist gleichzeitig Teil des Datensatztitels*: Bei den Kochrezepttexten ist das die Speisenbezeichnung, im Regimina-Korpus ergibt sich die jeweilige neuhochdeutsche Bezeichnung aus dem Namen des Monats, der im Text behandelt wird. Bei der Erhebung der Kochrezepttexte wurde außerdem versucht, mit den Datenfeldern Gericht bzw. Ingrediens regens eine Klassifikation der mittelalterlichen Speisen aufzustellen.28 Der historische Text (Rezepttext*) ist als plain text in einem Textfeld verspeichert.29 Diesem können eine oder mehrere Übersetzungen beigegeben werden. Verpflichtend ist natürlich die Angabe, für welche Pflanze der jeweilige Text eine Belegstelle darstellt: Dabei wird der Beleg-Datensatz beim Vergeben von Zutaten*-Tags (vgl. unten) automatisiert mit den jeweiligen damit verbundenen Pflanzennamen-Datensätzen verknüpft. Diese Zutaten-Tags müssen aus Gründen der vollständigen Quellentextbeschlagwortung und für eine über das PPM/MPS hinausgehende Textnutzung alle im Text genannten auch nicht-pflanzlichen Ingredienzien abbilden.
Da im Rahmen des Projektes generell angeregt wird, dass thematische Kleinkorpora für eine bessere Zusatznutzung der gesammelten Daten erstellt werden sollen, werden Quellentexte außerdem einem bestimmten Korpus* zugeordnet, um so gezielte Abfragen über eine thematisch definierte Textgruppe möglich zu machen. Eine weitere Grobeinteilung wird getroffen, indem die Texte zusätzlich textsortenbasiert beschlagwortet werden (Type*): Sie können den Großgruppen ‚diätetischer Text‛, ‚Kochrezepttext‛, ‚epische Dichtung‛, ‚lyrische Dichtung‛, ‚Kräuterbucheintrag‛ und ‚medizinisches Rezept‛ zugeteilt werden. Diese Zuordnung ist z. B. dann hilfreich, wenn eine Kochrezepttextsammlung, die Teil des Korpus der mittelalterlichen Kochrezepttexte ist, z. B. diätetische Kurztexte beinhaltet, da diese so zusätzlich zur Einordnung in ein Korpus vertiefend kategorisiert werden können.30
Zudem sind weitere beschreibende Felder für Rezeptliteratur vorhanden, z. B. für allfällige kulturhistorische Informationen. Die hier verspeicherten Daten sind sehr heterogen und können beispielsweise neben Serviervorschlägen auch im Text genannte materielle Informationen (z. B. spezielles Kochgeschirr) umfassen. Weitere kultur- und kulinarhistorische Fakten wurden für bereits durchgeführte oder geplante Spezialstudien als eigene Datenfelder implementiert: zur Verwendung von Gewürzen (Gewürzformel)31, Hinweise zur Zubereitung, textinterne Hinweise auf Kombinationsmöglichkeiten von Speisen (oder Heilmitteln), diätetische Informationen (Diätetik) oder Paralleltexte (Parallelen).
Datenbankfeld - Beschreibung
Titel: Der Titel setzt sich aus den Inhalten des Feldes ‚Bezeichnung‛ und der Handschriftensigle zusammen, die Informationen werden durch einen Gedankenstrich getrennt.
Manuskript: Handschriftensigle (Auswahlmenü)
Handschrift: Referenz zu einem bestimmten Abschnitt einer Handschrift
Folio: Folioangabe (spaltengenaue Referenz innerhalb einer Handschrift)
Rezeptnummer: Rezeptnummer aus der Edition, falls nicht vorhanden individuelle PPM/MPS-interne Nummerierung
Bezeichnung: Frei wählbarer aber aussagekräftiger Titel für den Quellenbeleg
Gericht: Kulturhistorische Information zu den Kochrezepttexten: Versuch einer Klassifizierung der mittelalterlichen Rezepte auf Basis der Zubereitungsart
Ingrediens Regens: Versuch einer Klassifizierung der mittelalterlichen Rezepte auf Basis der Hauptzutat.
Rezepttext: Quellentext
Sprache: Sprachstufe des Quellenbelegs
Kultur: Allfällige kulturhistorische Information zu den Kochrezepttexten
Korpus: Angabe eines Kleinkorpus, dem ein Quellentext zugeordnet ist
Speisenname: Kulturhistorische Information zu den Kochrezepttexten: historischer Name einer Speise
Gewürzformel: Kulturhistorische Information zu den Kochrezepttexten: formelhafte Würzanweisung
Zubereitung: Kulturhistorische Information zu den Kochrezepttexten: explizite Zubereitungsanweisungen
Kombinationen: Kulturhistorische Information zu den Kochrezepttexten: explizite Anweisung zu Speisenkombinationen
Diätetik: Kulturhistorische Information zu den Kochrezepttexten: explizite diätetische Informationen des Quellentextes
Parallelen: Kulturhistorische Information zu den Kochrezepttexten: Parallelüberlieferungen des Quellentextes
Type: Textgattungsspezifische Klassifizierung des Quellentextes (Auswahlmenü)
Checked: Interne Information zum Stand der Kollationierung des Belegtextes
Übersetzung: Übersetzung (Deutsch) des Quellentextes
Original Kommentar: Kommentarfeld
Kommentar: Kommentarfeld
Zutaten: Jegliche Ingredienz, die in einem Quellentaxt genannt wird
Zutaten-Tags
Für die Beschlagwortung der in den Quellentexten verwendeten Pflanzen (und allen weiteren Ingredienzien) wird auf technischer Ebene auf die WordPress-internen Beschlagwortungsmechanismen zurückgegriffen, da diese out of the box eine Indexübersicht der Schlagworte bieten, die auch die Verteilung der Tags verzeichnet und über diese numerische Angabe die Benutzenden direkten auf die entsprechenden Quellentext-Datensätze zugreifen lassen. Die pflanzlichen Zutaten sind außerdem intern mit den entsprechenden Entries (Pflanzennamen) verknüpft. Diese Schlagworte sind systeminterne Standardwerte: Sie verbessern die interne Suchbarkeit der Daten und schaffen zusätzlich ‚Mikro-Kategorien‛, indem über einzelne Schlagworte bestimmte Datengruppen hervorgehoben werden können: Für die bis dato gesammelten Texte sind das die neuhochdeutschen Bezeichnungen32 aller empfohlenen Nahrungsmittel bzw. der einzelnen Zutaten (vgl. Liste in Korpusdatenauswertung, Kap. 3.2.4), die in den Texten zusätzlich zu den Pflanzen genannt werden. Die Schlagworte werden nach folgenden Regeln vergeben:
- Tags werden grundsätzlich nur im Nominativ Singular verzeichnet, Ausnahmen bilden hier aus Gründen der besseren Datensuchbarkeit ‚Eier’ (vs. Ei) und aus Gründen der inhaltlichen Abgrenzung ‚Kräuter‛ (vs. ‚Kraut‛, das für die nicht näher bestimmbare Zutat Weißkraut / Kohl vergeben wird).
- Teile oder Produkte von Einzelzutaten bzw. Zutaten, die durch ein Attribut näher bestimmt werden, werden nach der Formel ‚Zutatenname (Teil / Attribut)‛ gebildet, wie z. B. „Alraune (Rinde)‟, „Ingwer (Pulver)‟, „Erbse (rot)‟. Gibt es für diese Pflanzenteile oder -produkte eine offizielle pharmazeutische Bezeichnung, wird diese bevorzugt, wie z.B. „Zimtblüte‟.
- Nicht näher bestimmbare pflanzliche Zutaten und andere nicht exakt bestimmbare Zutaten werden wie Pflanzennamen, die nicht exakt auf Artebene identifiziert werden können (vgl. Kap. 3.2.3), nach der Formel ‚Pflanzennamen, eine Art von ~‛ bezeichnet: z. B. „Enzian, eine Art von ~‟.
- Nicht identifizierbare historische Begriffe werden mit ‚?‛ vor und nach dem Tag gekennzeichnet: z. B. „?chachail wasser?‟, „?Birnen(leb)zelten?‟.
- Pflanzenzubereitungen, die über ein einfaches Weiterverarbeiten der Ausgangspflanzen (Mahlen, Pressen) hinausgehen, bekommen eigene Tags: z. B. „Veilchenöl‟, „Schafgarbenwasser‟.
Schlagworte können direkt bei der Eingabe von Quellentexten vergeben werden, wobei das Eingabefeld, in das mehrere durch Beistrich getrennte Schlagworte eingegeben werden können, Vorschläge zur Autovervollständigung von Schlagworten gibt, sodass bereits bestehende Schlagworte in der korrekten Schreibweise übernommen werden können. Zusätzlich können Schlagworte gesondert aufgelistet und auch einzeln bearbeitet werden. Diese Funktion bietet außerdem die Möglichkeit einzelne Einträge zu kommentieren: Für die Zutat kapfwais wird hier zum Beispiel vermerkt, dass es sich um eine Verschreibung von fnhdt. kalbswais handeln könnte.33
Dateneingabe
Die Dateneingabe ist durch die benutzerfreundliche Orientierung, die das CMS WordPress bietet, sehr einfach: Das Hauptmenü im Kopfbereich bietet die Möglichkeit, mit dem Link „+ Neu‟ über eine Drop-down-Liste ein leeres Datenblatt einer beliebigen Datenkategorie zu öffnen. Jedes geöffnete Datenblatt und jede Indexseite eines Datenbereiches hat in Form eines Links „Erstellen‟ eine Funktion, ein leeres Datenblatt der selben Kategorie zu öffnen. Jeder einzelne Datenbereich des Seitenmenüs verfügt über einen Link „Erstellen‟, über den ein leeres Datenblatt der jeweiligen Kategorie aufgerufen werden kann. Gleichzeitig öffnet jeder geschlossene Menüpunkt mittels Mouse-over-Funktion die Liste der Unterpunkte, die für alle Datenkategorien einen Link zum Öffnen eines leeren Datenblattes aufweisen.
Für die Eingabe neuer Daten gibt es im Grunde nur eine umfassend gültige Regel: Jede Eingabe neuer Daten muss durch einen Klick auf den Button „Veröffentlichen‟ (für das Anlegen neuer Datensätze) bzw. „Aktualisieren‟ (für das Speichern von Änderungen in bereits angelegten Datensätzen) auf der rechten Seite der Website bestätigt werden. WordPress erlaubt softwareseitig zwar auch das Verspeichern unvollständiger Datensätze, doch fallen diese, wenn die nötigen Felder nicht ausgefüllt sind, aus dem projektintern vorgegebenen Datenraster. Daher müssen beim Anlegen neuer Datensätze bestimmte Daten ohne diese Information kann kein neuer Datensatz in die PPM/MPS-Datenstruktur oder die CMS-Struktur eingegliedert werden. Zusätzlich gibt es für die einzelnen proprietären Datenbereiche Pflichtfelder, die mit Daten gefüllt werden müssen: Die oben bei der Beschreibung der einzelnen Datenbereiche angegebenen Pflichtfelder gelten ausschließlich für das PPM/MPS-Datenmodell: Werden die Pflichtfelder nicht ausgefüllt, kann es in weiterer Folge zu Problemen bei der Datenpräsentation im Front-End kommen: So ist z. B. die Anzeige der Edition, der ein Quellentext entnommen wurde, von der Verknüpfung mit einer Handschrift abhängig.felder ausgefüllt werden: Datensatzübergreifend gilt diese
Regel für das Titel-Feld, denn Freitextfelder und Kommentarfelder bieten überdies die Möglichkeit, die dort gespeicherten Daten durch rudimentäres Format-Mark-up auszuzeichnen: Neben einzelnen Formatvorlagen, mit denen vollständige Textpassagen definiert werden können, kann das Schriftbild verändert werden (kursiv, fett, unterstrichen, durchgestrichen, Textfarbe), nummerierte und Punktelisten angelegt werden, die Zeilenausrichtung kann angepasst werden und Hyperlinks können im Fließtext definiert werden. Die Menüleiste bietet zusätzlich noch medienspezifische Elemente (Formatierung ‚Zitat‛, Weiterlesen-Link, Bilder einfügen etc.) und software-organisatorische Hilfsmittel (Vollbildmodus, Ein- und Ausblenden der Werkzeugleiste).
Die Präsentation der PPM/MPS-Datenkategorien im Front-End des MPS-Repository
Pflanzennamen
Der Link „Pflanzennamen‟ des Hauptmenüs im MPS-Repository öffnet eine Seite mit einer Übersicht der Pflanzennamenindices, die neben den Bezeichnungen der einzelnen Sprachen und Sprachstufen, die als Link zur alphabetischen Übersichtsliste der Pflanzennamen angelegt sind, auch die Anzahl der für einen Index vorhandenen Pflanzennamen anzeigt. Jede dieser Indexlisten bringt einleitend eine Kurzbeschreibung der jeweiligen Sprachstufe, daran anschließend die alphabetische Liste der Pflanzennamen. Jeder dieser Namen ist ein Link zum eigentlichen Datenblatt des Pflanzennamens.
Die Darstellung dieser Datenseiten ist immer nach demselben Muster aufgebaut und soll für die Pflanzennamen deren Platz innerhalb der historischen Überlieferung abbilden: Der Kopf des Datenblattes besteht aus dem Pflanzennamen selbst, der Zuordnung zu einer Sprachstufe und der temporalen und lokalen Einordnung derselben. Das Zentrum einer Seite bilden die Listen der mit diesem Namen etymologisch und semantisch verknüpften Pflanzennamen, diese werden in parallele, untergeordnete und übergeordnete Sprachstufen untergliedert, um die einzelnen Abhängigkeitsverhältnisse besser darzustellen. Diese sind für die im PPM/MPS vorhandenen Sprachstufen wie auf der Grafik dargestellt verteilt:
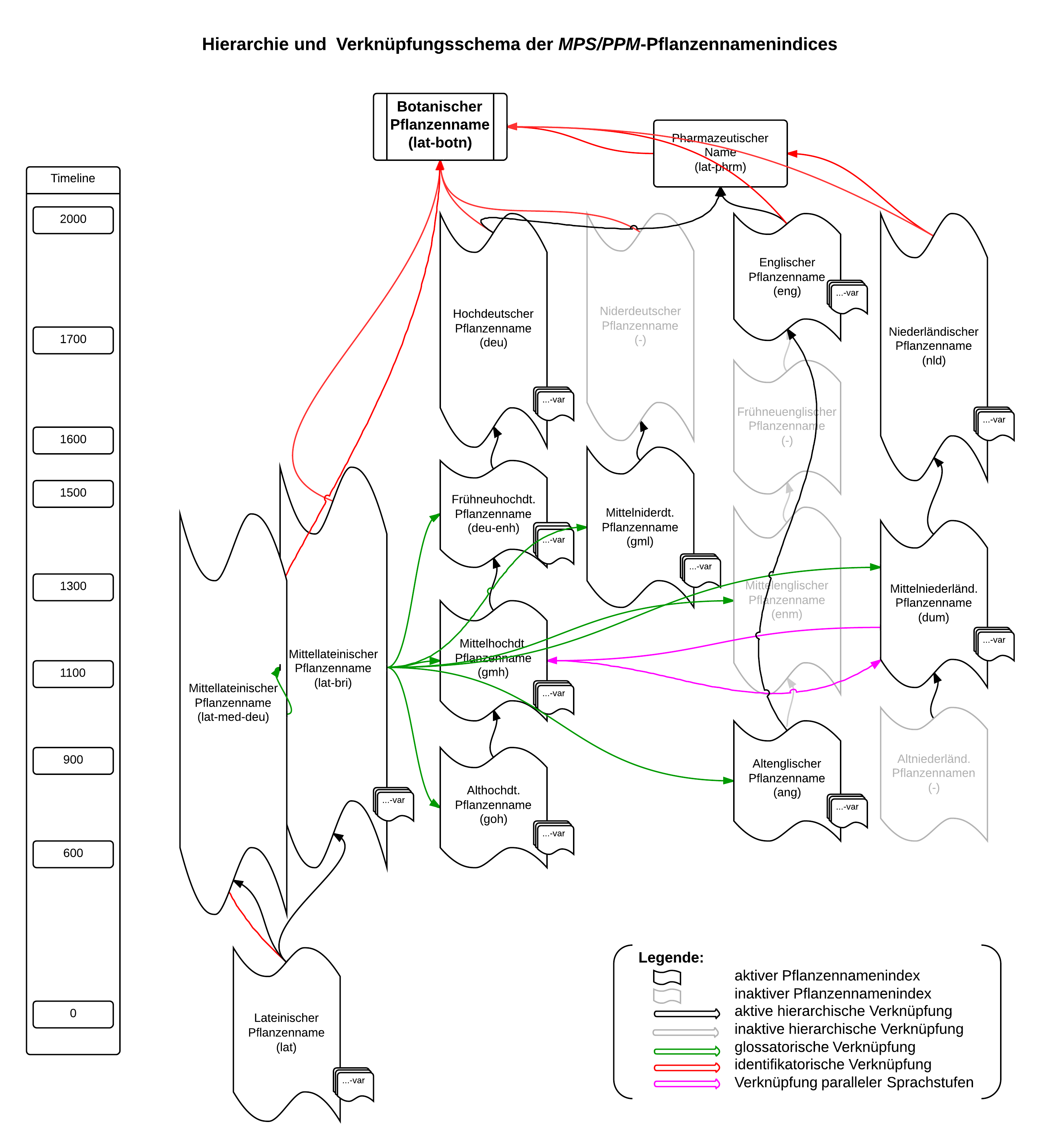
MPS-Language-Schema
Jeder der nach den Zwischenüberschriften, welche die jeweilige Sprachstufe benennen, angezeigten Pflanzennamen ist ein Hyperlink und öffnet das jeweilige Datenblatt.
Die Pflanzennamen sind dafür auf Basis letztgültiger Forschungsergebnisse zur Identifikation historischer Pflanzennamen miteinander vernetzt, sodass z. B. eine diachrone Entwicklung eines Pflanzennamens ausgehend von allen Sprachstufen über die verspeicherten Relationen nachvollziehbar sein kann. Gleichzeitig erlaubt es die oben getroffene Einteilung, dass Pflanzennamen auch auf synchroner Ebene in parallelen Sprachstufen unterschiedlicher Sprachen gegenübergestellt werden können, sodass die sprachenübergreifenden Zusammenhänge – oder die Unterschiede – erstmals für das gesamte Namenmaterial dargestellt werden können. Diese Relationen beinhalten zudem nicht nur sprachlich verwandte Namen, sondern bilden auch semantische Abhängigkeiten ab. Diese mehrdimensionale Vernetzung macht die Darstellung und Überprüfung etymologischer Zusammenhänge über Sprachgrenzen hinweg mit einigen wenigen Klicks möglich. Zusätzlich sind mit den einzelnen Pflanzennamen auch alle relevanten Quellenbelege verknüpft und werden so automatisch in den durch die Sprachstufen vorgegebenen Zeitraster mit einbezogen; das erleichtert alle notwendige analytisch-interpretatorische Arbeit.
Quellentexte
Der Link „Texte‟ des Hauptmenüs öffnet eine Seite mit einer Übersicht der vorhandenen Quellentexte. Diese sind alphabetisch nach Datensatztitel aufgelistet. Jeder Titel ist ein Hyperlink und öffnet die Datenblattansicht des Quellentextbelegs. Diese ist nach folgendem Muster aufgebaut: Den Kopf des Datenblattes bilden der Titel als Überschrift und die ID des Datensatzes. Darauf folgten die Referenzdaten: die Angaben zum untergeordneten Textkorpus (als Hyperlink, der eine Übersicht der Texte dieses Korpus öffnet), der Quellenhandschrift (als Hyperlink, der das Datenblatt zur Handschrift öffnet) mit Folioangabe und der aktuellsten Edition mit Angabe der Rezeptnummer. Der Hauptteil dieses Datenblattes ist der Belegtext selbst, der jeweils in der Originalsprache angezeigt wird.
Außerdem gibt es in einem durch Mausklick aufklappbaren Bereich am Ende der Datenübersicht einen Überblick über die gesammelten Forschungsdaten, die zum Teil aber noch nicht durchgehend für alle Texte erhoben worden sind. Die Rubrik ‚Description‛ beinhaltet den neuhochdeutschen Titel des Quellentextes und mit den Angaben zur Hauptzutat (Ingrediens regens) und der Speisegattung (Food) den Versuch einer Kategorisierung der historischen Gerichte. Die Rubrik ‚Analysis‛ führt als Unterpunkt die Daten zu Würzinformationen; die Rubrik ‚Parallelüberlieferungen‛ enthält Informationen zur weiteren Überlieferung des Quellentextes.
Pflanzendarstellungen34
Der Link „Darstellungen‟ des Hauptmenüs öffnet eine Seite mit zwei exemplarischen Sammlungen von bildlichen Pflanzendarstellungen, die aufgrund ihrer unterschiedlichen Herkunft die Varianz in der mittelalterlichen Pflanzendarstellung veranschaulichen sollen. Die Bildersammlung zu den vegetabilen Gewölbemalereien der Pfarrkirche in St. Marein bei Knittelfeld in der Steiermark ist gleichzeitig digitales Begleitmaterial zu einem fachwissenschaftlichen Aufsatz.35 Eine weitere Seite zeigt Bilder aus dem Herbarius Latinus des Peter Schöffer.[fn. Peter Schöffer: „Herbarius Latinus”. Mainz, 1484. Vorlage: Universitätsbibliothek Erlangen-Nürnberg (Sammlung Trew). CD-Rom. Erlangen: Fischer 2006.]
Handschriften
Der Link „Handschriften‟ des Hauptmenüs öffnet eine Seite mit einer alphabetisch geordneten Liste von Handschriftensiglen, die jeweils wiederum als Hyperlink dienen, der die Datenblattansicht eines Handschriftendatensatzes öffnet. Diese sind nach folgendem Muster aufgebaut: Den Kopf des Datenblattes bilden die Handschriftensigle als Überschrift und die ID des Datensatzes. Die Handschriften sind einerseits durch temporal (Date of Origin), lokal (Place of Origin) und sprachlich (Dialect) kategorisierende Informationen beschrieben und andererseits (Description) durch die klassischen kodikologischen Informationen zu Beschreibstoff, Umfang, diverse Abmessungen, Spaltenanzahl, Zeilenumfang, Schreiber- bzw. Handschriftbestimmung, Hinweis auf allfällige Verzierungen bzw. Buchmalereien, Wasserzeichen und Entstehungszeit. Diese Beschreibung schließt in der Regel mit einem externen Hyperlink zum Handschriftencensus.36 Die Zusammenfassung des Inhalts versucht in Bezug auf die Texte der Handschrift möglichst umfassend zu sein, ohne inhaltlich aber zu sehr ins Detail zu gehen: Verzeichnet sind die Foliobereiche und die Titel der einzelnen Texte. Die Beschreibung der Kochrezepttextsammlung gibt einen Überblick zum Aufbau der jeweiligen Sammlung. Auf diese zusammenfassenden Informationen folgt die dafür verwendete Referenzliteratur. Dazu wird eine Aufstellung der verfügbaren Kochrezepttextsammlungseditionen, die jeweilige Kochrezepttextsammlungssigle, die Anzahl der Kochrezepttexte und der Kurztitel der den Quellentextdatensätzen zugrundeliegenden Printpublikation gestellt. Benutzer mit Administratorenrechten haben außerdem Zugriff auf die nach Rezeptnummer geordneten Quellentexte einer Handschrift.
Information-Retrieval im PPM/PMS-Webauftritt
Browsing
Alle Inhalte des PPM/MPS können von Benutzenden, die einen ersten Überblick gewinnen wollen, über das Front-End des MPS-Repositorys browsend erschlossen werden. Die oben beschriebene Struktur des MPS-Repository ist perfekt dafür geeignet, diesen unstrukturierten Zugang zu unterstützen. Für eine stärker fokussierende Arbeit mit den vorhandenen Daten bietet WordPress verschiedene Suchroutinen an.
Suchroutinen
Back-End
Im Back-End gibt es auf den Übersichtsseiten der einzelnen Datenrubriken (Beiträge, Medien, Links, Seiten, Kommentare, Druckwerke, MPS Languages, Entries, Manuscripts, Recipes) Suchfelder, die dazu genutzt werden können, die aufgelisteten Datensatztitel zu durchsuchen und damit die angezeigten Daten nach eigenen Parametern einzuschränken. Um darauf zugreifen zu können, benötigt man aber die entsprechende Berechtigung.
Front-End
Über das Lupen-Icon können im Front-End des MPS-Repositorys zum Durchsuchen der Datensätze zwei Abfrageroutinen aufgerufen werden, die auf unterschiedliche Datenbereiche zugreifen: die Simple Search und die Advanced Search.
Die Simple Search ist jene Suchroutine, die systemintern angeboten wird. Sie ist daher auch ausschließlich auf die vom System vorgegebenen Datenfelder ‚Datensatztitel‛ und ‚Freitextfeld‛ von Posts, Pages und Custom Post Types beschränk. Die Suche wird allerdings über alle vorhandenen Datensätze aller Datenrubriken ausgeführt. Die eingegebenen Suchbegriffe werden in Form einer unscharfen Suche weiterverarbeitet, was die Trefferanzahl erhöhen soll. Dabei werden auch Treffer angezeigt, die nicht genau mit dem Such-String übereinstimmen. So kann der Suchbegriff zum Beispiel nur eine Teilmenge eines Treffers sein: Die Suche nach dem String ‚blau‛ erzielt 72 Treffer, die neben den Pflanzennamen „Blaufleckernder Purpur-Röhrling‟, „Knoblauch‟ und „Blauer Eisenhut‟ auch die Titel von Quellentexten auswirft: „Knoblauchsauce zu Huhn, Morcheln, Pilzen – Dessau, Anhaltische Landesbücherei, Hs. Georg. 278.2°‟ oder „Wildschweinkopf mit höllischen Flammen – Wien, Österreichische Nationalbibliothek, Cod. vind. 4995‟ – beim letzten Beispiel enthält das Freitextfeld des Datensatzes eine Notiz zur Nennung von blauer Farbe im Rezepttext. Mit diesem Hintergrundwissen können mit der Simple Search unter Benutzung bewusst gewählter und kombinierter Suchbegriffe sehr gute Ergebnisse erzielt werden.
Die Trefferliste wird mit der Information zur Gesamttrefferzahl und der Wiederholung des Suchbegriffes eingeleitet und zeigt ausschließlich die Datensatztitel an. Diese leiten als Hyperlinks zu den einzelnen Datenblättern weiter.
Um jedoch jene Inhalte abfragen zu können, die über die Datenfelder der Custom Post Types verspeichert sind, gibt es mit der Advanced Search eine Suchfunktion, die es ermöglicht, für die Pflanzennamen und auch für die Quellentexte Primär- und Metadatenfelder einzeln oder in beliebiger Kombination zu durchsuchen. Die Suche nach den Pflanzennamen und das Suchformular für die Quellentexte sind zwei getrennte Suchen, die allerdings über einen Bestätigungsbutton aktiviert werden. Ist das Suchfeld der Pflanzennamensuche ausgefüllt, werden alle anderen Angaben im weiteren Suchformular ignoriert.
Die Suche nach Pflanzennamen bietet ein einziges Suchfeld, über welches das Korpus der gesammelten Pflanzennamen durchsucht werden kann. Ausgehend von der Datenkonvention dieser Rubrik wird nur das Titelfeld der Datensätze durchsucht. Wie bei der systeminternen Suche wird auch hier der Modus der unscharfen Suche angewandt. So erzielt die Suche nach dem String ‚blau‛ 10 Treffer, die u. a. folgende Pflanzennamen umfassen: Knoblauch, Gewöhnliche Blaue Himmelsleiter, reblaub. Die Trefferanzeige eröffnet mit einem Hyperlink „Suchanfrage ändern‟, der auf das vorausgefüllte Suchformular zurückleitet. Die Suchergebnisse werden in einer nummerierten Liste angezeigt; jedem Pflanzennamen ist in runden Klammern das entsprechende Sprachenkürzel nachgestellt: z. B. „5. Blauer Eisenhut (deu)‟.
Die Suche in den Quellentexten bietet dem Benutzer mehr Optionen, wobei folgende Datenfelder des Custom Post Types, die für eine Suchanfrage auch miteinander kombiniert werden können, angeboten werden:
Datenfeld-Beschreibung
Manuscript:
Aus einer alphabetisch geordneten Drop-Down-Liste kann für dieses Datenfeld eine beliebige Handschriftensigle ausgewählt werden. Wird die Auswahl mit dem „Senden‟-Button abgeschickt, öffnet sich das Datenblatt zur jeweiligen Handschrift.
Dieses Datenfeld kann mit anderen Feldern in einer Suchabfrage kombiniert werden, wobei aber wohl nur bestimmte Kombinationen produktive Ergebnisse liefern werden:
- Folio: Damit kann ein bestimmter Text auf einer bestimmten Handschriftenseite angezeigt werden. Für produktive Suchen sollten Benutzende über den Umfang und Aufbau einer Kochrezepttextsammlung Bescheid wissen. Mit dieser kombinierten Suche können gezielt Texte auf bestimmten Handschriftenseiten aufgerufen werden. Kennt man die genaue Referenzierung eines Textes nicht, wird diese Kombination keine produktiven Ergebnisse liefern und man kann Suchabfragen nur auf gut Glück absenden. Diese Einschränkung gilt gleichermaßen für die Felder ‚Rezeptnummer‛ und auch ‚Post ID‛.
- Bezeichnung: Diese Kombination listet alle Datensätze einer Handschrift, die einen bestimmten Begriff im neuhochdeutschen Rezepttitel führen.
- Rezepttext: Durch diese Kombination kann man sich beliebige Wortformen in Texten einer Handschrift anzeigen lassen. Die Texte sind nicht lemmatisiert, sodass aufgrund der hohen Varianz in der Schreibung keine genauen Suchergebnisse zu erwarten sind.37
- Texttyp: Ein Drop-Down-Menü bietet die zur Zeit verspeicherten Texttypen (cooking recipe, dietetics) zur Auswahl an: Durch diese Kombination kann z. B. die Anzahl diätetischer Rezepte, die in einer Kochrezepttextsammlungen aufgezeichnet sind, herausgefunden werden.
- Zutat: Mit dieser Kombination können jene Rezepte einer Handschrift gefunden werden, die nach bestimmten Zutaten oder Zutatenkombinationen (beistrichgetrennte Mehrfacheingabe ist möglich.) verlangen.
Folio:
Hier kann als Suchbegriff eine beliebige Folioangabe eingegeben werden, was – sofern diese Daten vorhanden sind – Quellentexte aus unterschiedlichen Handschriften mit übereinstimmender Folioangabe anzeigt. Als produktive Kombination bietet sich hier nur das Feld Handschriften an; es ist zudem von Vorteil, wenn Benutzende genaue Angaben haben, die gesucht werden sollen. Diese Suchkombination kann verwendet werden, um gezielt Texte zu suchen.
Rezeptnummer:
Dieses Feld ist auf produktive Weise nur in Verbindung mit der Angabe einer Handschrift zu verwenden: Voraussetzung für verwertbare Ergebnisse ist auch hier, dass Benutzende die entsprechenden Referenzdaten kennen. Diese Suchkombination kann verwendet werden, um gezielt Texte zu suchen.
Bezeichnung:
Über dieses Suchfeld können Benutzende die neuhochdeutschen Titel der Quellentexte durchsuchen; es eignet sich besonders für thematisch orientierte Suchen. Dieses Feld kann für selektivere Ergebnisse mit folgenden Feldern kombiniert werden:
- Texttyp: Das schränkt die Treffer momentan wahlweise auf Kochrezepttexte oder Texte mit diätetischem Inhalt ein.
- Zutat: Durch die Angabe von Zutaten, die ein einem Quellentext genannt werden müssen, können die Treffer eingeschränkt / verfeinert werden.
Rezepttext:
Mit diesem Suchfeld können die historischen Quellentexte durchsucht werden. Da diese nicht lemmatisiert sind, wird das Ergebnis oft nicht aussagekräftig sein; Abhilfe schaffen könnte, mit Teilen historischer Wörter zu suchen.
Diese Suche kann z. B. verwendet werden, um die Verteilung historischer Schreibweisen im Korpus zu überprüfen. Mögliche Kombinationen für produktive Suchen wurden oben schon genannt, weiters könnte z. B. die Kombination mit dem Datenfeld ‚Texttyp‛ verwertbare Ergebnisse liefern.
Texttyp:
Hier können über ein Drop-Down-Menü Bezeichnungen für unterschiedliche Textsorten ausgewählt werden. Mögliche Kombinationen mit anderen Datenfeldern wurden oben bereits genannt, weiters kann z. B. eine Suche durch die Kombination mit einzelnen Zutaten verfeinert werden.
Zutaten:
Über dieses Feld können die Zutaten der Kochrezepttexte abgefragt werden; es eignet sich besonders für inhaltlich orientierte Suchen. Das Suchfeld kann auch mit mehreren durch Beistrich getrennten Begriffen gefüllt werden: „Fisch, Zwiebel‟ findet Quellentexte, in denen diese Begriffe genannt werden. Mögliche Kombinationen wurden oben bereits genannt.
Post ID:
Über dieses Feld kann durch die Eingabe einer Post ID (Diese werden für Quellentexte automatisch nach dem Muster ‚S######‛ generiert.) gezielt ein bestimmter Quellentextdatensatz aufgerufen werden. Diese Funktion ist hilfreich, wenn in externen Texten Inhalte des PPM/MPS referenziert werden sollen: Anstelle langatmiger Textreferenzen und URLs können diese einfach durch die Angabe der Post ID referenziert und über das Suchformular auch aufgerufen werden.
Datenfreigabe: User Level des MPS-Repository
Content Management Systeme bieten die Möglichkeit, unterschiedliche Benutzergruppen mit unterschiedlichen Rechten zu definieren. Für den Webauftritt des PPM/MPS gibt es drei Zugangsebenen, in denen Benutzende unterschiedliche Rechte haben:
Das User-Level ‚public‛, das automatisch auf alle unregistrierten bzw. auf alle nicht am System angemeldeten Benutzenden angewandt wird, stellt die unterste Zugangsebene dar und bietet daher nur sehr eingeschränkten Zugriff auf die im PPM/MPS gespeicherten Daten. Benutzer mit diesem Status haben Zugang zu folgenden Inhalten der Website:
- Vollzugriff auf alle Beiträge der Blogoberfläche
- Vollzugriff auf alle Posts im Front-End des Repositorys
- Vollzugriff auf alle Pflanzendarstellungen
- Vollzugriff auf alle Druckwerken
- Eingeschränkten Zugriff auf Pflanzennamen (Indexübersicht, Pflanzennamenindex, Pflanzenname mit linguistischen Eckdaten)
- Eingeschränkten Zugriff auf Quellentexte (Indexliste, Referenzdaten)
- Eingeschränkten Zugriff auf Handschriftendaten (Indexliste, Lokalisierungsdaten)
- Simple Search
Benutzende, die am System registriert und angemeldet sind, befinden sich im User-Level ‚basic‛ und haben folgende Leseberechtigungen:
- Vollzugriff auf alle Beiträge der Blogoberfläche
- Vollzugriff auf alle Posts im Front-End des Repositorys
- Vollzugriff auf alle Pflanzendarstellungen
- Vollzugriff auf alle Druckwerken
- Vollzugriff auf alle Pflanzennamen
- Vollzugriff auf alle Quellentexte
- Vollzugriff auf alle Handschriftendaten
- Simple Search
- Advanced Search
Mitglieder der Benutzergruppe ‚User-Level ‚advanced‛, für die einerseits die Registrierung und Anmeldung am System und andererseits eine persönliche Kontaktaufnahme zum Seitenadministrator für eine erweiterte Rechtevergabe vorausgesetzt werden, haben folgende Lese- und Schreibrechte:
- Vollzugriff auf alle Beiträge der Blogoberfläche
- Vollzugriff auf alle Posts im Front-End des Repositorys
- Vollzugriff auf alle Pflanzendarstellungen
- Vollzugriff auf alle Druckwerken
- Vollzugriff auf alle Pflanzennamen
- Vollzugriff auf alle Quellentexte
- Vollzugriff auf alle Handschriftendaten
- Simple Search
- Advanced Search
- Lesen aller Daten im Back-End des MPS-Repository
- Bearbeiten aller Daten im Back-End des MPS-Repository
- Anlegen neuer Daten im Back-End des MPS-Repository
Datenimport und -export
Import
Die Arbeitspraxis der letzten Jahre hat gezeigt, dass die Aufbereitung großer Textmengen für die Eingabe in die Datenbank wesentlich schneller offline mithilfe eines herkömmlichen Tabellenverarbeitungsprogrammes durchgeführt werden kann, als dies bei der aufeinanderfolgenden manuellen Einspeisung einzelner Belegtexte der Fall ist. Gleichzeitig bieten derartige Listen durch die parallele Darstellung eine bessere Übersicht bei der Ersterhebung bzw. Erstbeschreibung von Daten. Die offline generierten Daten können über die online zur Verfügung gestellten, normierten Importroutinen in die Datenbank eingespeist werden. Ausgehend von dem in Kap. 4 im Detail skizzierten idealtypischen Ablauf der Datenrecherche und -erfassung (1. Einpflegen der Pflanzennamen, 2. Sammeln von Quellentexten und Vernetzen mit Pflanzennamen, 3. Beschreibung, Interpretation und Auswertung der Daten) dienen die auf der Website angebotenen Werkzeuge nach erfolgter initialer Verspeicherung der Datensätze in der Datenbank primär zur verfeinernden Bearbeitung der Daten, indem diese mithilfe vertiefender Metadaten beschrieben werden, und vor allem zu einem weiteren Vernetzen zusammengehöriger Datensätze. Zusätzlich dient der Online-Arbeitsplatz der Ausarbeitung und Klärung von Recherchefragen, wofür unter anderem die unterschiedlichen Suchroutinen (vgl. Kap. 3.5.2) zur Verfügung stehen.
Export
Für einen Export werden verschiedene vordefinierte Abfragen angeboten: Einzelne Tabellen der Datenbank (wie z. B. die Pflanzennamenindexlisten) können als CSV-Dateien heruntergeladen werden (Back-End – Werkzeuge – MPS Export). Für den Export großer Datenmengen ist in jedem Fall die Rücksprache mit den Seitenbetreibern notwendig. Bei konkretem Bedarf eines Datenaustausches werden allfällige Exportroutinen aber individuell mit den jeweiligen Kooperationspartnern abgesprochen: Der Datenaustausch, wie zum Beispiel jener der mittelhochdeutschen Pflanzennamen im PPM/MPS Datenpool für eine Vernetzung mit dem entsprechenden Einträgen des Conceptual System der MHDBDB, erfolgt über individuelle Anknüpfungspunkte, die entsprechenden Daten werden z. B. als XML-Export-File weitergegeben.
Text als PDF (Originalfassung):
Klug, Helmut W. – Dissertation – Pflanzen in deutschsprachigen Texten des MA – PPM-MPS-Auszug
Fußnoten:
- Die Ergebnisse der Vorüberlegungen, die hier verschriftlicht sind, wurden auch im Rahmen der Digitalen Bibliothek: Metadaten und Vokabularien (Graz, 24-25.11.2011) als Poster präsentiert. ↩
- Diese Ausdrücke stehen in Zusammenhang mit dem Ablauf des Abrufens von Daten von einem Server durch eine Browseranfrage: Während dieses mehrstufigen Prozesses können an bestimmten Stationen bestimmte Aktionen (actions) ausgeführt werden, die den vordefinierten Ladevorgang modifizieren. Filter (filters) werden an ähnlichen Stellen eingesetzt, dienen aber dazu, die während des Ladevorganges abgerufenen Daten zu modifizieren. ↩
- Ein einfaches Beispiel dafür wären z. B. Tag-Clouds. ↩
- Die Begriffe ‚strukturiert‛ und ‚unstrukturiert‛ verweisen hier auf die spezifischen Abhängigkeiten (Relationen) von Posts und Pages untereinander und vom Gesamtsystem. ↩
- Vgl. Create a Network (01.09.2014). ↩
- Das ist der administrative Teil der PPM/MPS-Webpräsenz. ↩
- Das ist der öffentlich zugängliche Teil der PPM/MPS Webpräsenz. Vgl. Wikipedia, s. v. Front-End und Back-End (01.09.2014). ↩
- Das ist jener Teil der PPM/MPS Webpräsenz, der in Teilen für registrierte Benutzer und in seiner Gesamtheit für Benutzer mit Administratorenberechtigung zugänglich ist. ↩
- Das ist der öffentlich zugängliche Teil des MPS-Repository. ↩
- Das ist der administrative Teil des MPS-Repository. ↩
- Diese wurden aus organisatorischen Gründen zur Dateneingabe für Studierende einer Lehrveranstaltung implementiert. ↩
- Für den Internetauftritt des PPM/MPS wird das professionell erstellte Theme ‚Dorayaki‛ der Firma Elmastudio verwendet; das Theme ist für die Darstellung textorientierten Contents optimiert. Außerdem ist es responsiv, d.h. die Anordnung der Elemente der Website-Oberfläche passt sich der Bildschirmauflösung des jeweiligen Endgerätes an, sodass immer ein möglichst optimales Rezipieren der Inhalte ermöglicht wird. ↩
- Eine detaillierte Beschreibung der Bearbeitungs- und Eingabemöglichkeiten erfolgt unten bei der Beschreibung der Custom Post Types des MPS-Repositorys. ↩
- Medieval Plants Group. In: Flickr – Photo Sharing. ↩
- Datenbereiche sind in WordPress durch ein graues Stecknadel-Icon gekennzeichnet. ↩
- Zusätzlich gibt es Datensätze, die den Status ‚Entwurf‛ haben, bzw. Datensätze, die aus der Indexliste gelöscht wurden, aber noch im nicht entleerten Papierkorb zugänglich sind. ↩
- Bei der herkömmlichen CMS-Funktionalität (z.B. im MPS-Blog) beinhaltet dieses Feld den Text des jeweiligen Posts, projektintern fallen diesem Feld unterschiedliche Rollen zu, die bei den einzelnen Datenbereichen vorgestellt werden. ↩
- Zusätzlich zu den verbalisierten Hinweisen markiert der * die Pflichtfelder der einzelnen Datenkategorien, weiterführende Informationen zu Pflichtfeldern gibt es im Kapitel „Dateneingabe‟ bzw. in der tabellarischen Übersicht zu den einzelnen Datenfeldern der PPM/MPS-spezifischen Datenmodelle. ↩
- Online werden die einzelnen Felder mit englischen Begriffen bezeichnet, da das Software-Modul aus einem englischsprachigen Vorgänger-Projekt übernommen wurde. Die Implementierung einer englischen Bearbeitungsoberfläche, die parallel neben der deutschen steht, ist einer der nächsten geplanten Erweiterungsschritte. ↩
- Hier wird durchgehend auf die entsprechenden Artikel in Wikipedia verwiesen: Diese bieten nicht nur die umfassendsten Informationen, sondern sind auch mehrsprachig vorhanden. Das sind Vorteile, die z. B. universitäre Seiten – sofern es solche überhaupt gibt – nicht bieten. Zusätzlich überzeugt die Wikipedia im Gegensatz zu vielen universitären Informationsseiten durch eine hohe Linkpersistenz. ↩
- Ist nur ein Pflanzenname in der Datenbank, wird die Singular-Form verwendet („Es ist ein deutscher Pflanzenname vorhanden.“), gibt es mehrere, die Plural-Form („Es gibt 20 deutsche Pflanzennamen.“) ↩
- Pflanzennamen, die nicht eindeutig identifiziert werden können, sind durchgehend dem neuhochdeutschen Eintrag „ungeklärt‟ zugewiesen. ↩
- Die hier verspeicherten Daten fassen die Handschriftenbeschreibungen der einzelnen Editionen aus den entsprechenden Bibliothekskatalogen zusammen und sammeln weitere Informationen aus Marianne Honold: Studie zur Funktionsgeschichte der spätmittelalterlichen deutschsprachigen Kochrezepthandschriften. Würzburg: Königshausen & Neumann 2005. (= Würzburger medizinhistorische Forschungen. 87.) und Constance Hieatt (u. a.): Répertoire des manuscrits médiévaux contenant des recettes culinaires. In: Du manuscrit à la table. Hrsg. v. Carole Lambert. Montreal und Paris: Les Presses de l’Université de Montreal und Champion-Slatkine 1992, S. 315-62 sowie den einzelnen Editionen zu den Kochrezepttextsammlungen, die teilweise zusätzliche Informationen liefern (vgl. dazu Kap. 3.1.5). ↩
- Bei Kochrezepttexten ist das in der Regel eine moderne Bezeichnung der Speise, die meist die Hauptzutat eines Gerichtes oder, sofern vorhanden, den historischen Namen nennt: Beispiele für derartige Bezeichnungen sind „Kalbslunge, gebacken – Wien, Österreichische Nationalbibliothek, Cod. vind. 5486‟ (ID: S64342) – Hauptzutat und „Fürhes, Hase – Wien, Österreichische Nationalbibliothek, Cod. vind. 2897‟ (ID: S63958) – historischer Name. Dabei wird das Substantivum regens vorangestellt, damit es für die alphabetische Reihung der Datensätze herangezogen werden kann. ↩
- Ausnahmen können hier frühe Drucke darstellen. ↩
- Rezeptnummern werden meist von Edierenden individuell vergeben und können numerische, aber auch alphanumerische Werte sein. ↩
- Diese Angaben werden ohne trennende Leerzeichen eingegeben: z. B: „50r‟. Sie sind außerdem ausschließlich für jene Kochrezepttextsammlungen verspeichert, die diese Informationen im Editionstext transportieren. ↩
- Aufgrund der großen kulturellen Unterschiede der mittelalterlichen Küche zur heutigen gestaltete sich dieser Prozess durchwegs schwierig, sodass eine letztgültige Einteilung hier noch nicht getroffen werden konnte: Das muss die Aufgabe zukünftiger kulinarhistorischer Forschung sein. ↩
- Dieser Text ist nicht lemmatisiert. ↩
- Als Beispiel für einen solchen Eintrag kann der folgende Text genannt werden: „Bekömmliche Speise (Diätetik) – Augsburg, Universitätsbibliothek, Öttingen-Wallerstein III.1.2° 43‟ (ID: S65399). ↩
- Vgl. Helmut W. Klug: ‘gewürcz wol vnd versalcz nicht’. Auf der Suche nach skalaren Erklärungsmodellen zur Verwendung von Gewürzen in mittelalterlichen Kochrezepten. In: Medium Aevum Quotidianum 61 (2011), S. 56-83 oder Julia Pia Zaunschirm: „vnd versaltz niht“. Salz als Ingredienz in mittelalterlichen Kochrezepttexten. Graz: Univ., Bakk.arb. In: KuliMa – kulinarisches Mittelalter Graz. Wissenschaftliche Arbeiten. 2012. (07.03.2012). ↩
- Diese wurden den historischen Bezeichnungen vorgezogen, um die Texte für eine breite Öffentlichkeit aufzuschließen. Eine Verknüpfung mit den historischen Pflanzennamen erfolgt systemintern. ↩
- Vgl. dazu eine Diskussion in der Mailingliste ‚Mediaevistik‛ im Januar 2014, die von Katharina Zeppezauer-Wachauer, einer Mitarbeiterin der MHDBDB, angeregt wurde: The Mediaevistik Archives. Zuletzt geändert August 2014. (08.08.2014). ↩
- Diese Rubrik ist im aktuellen Zustand als Platzhalter für eine zukünftige Datenkategorie eingefügt. ↩
- Helmut Hundsbichler, Helmut W. Klug: Dämonen im Presbyterium: Christliche Didaktik und Katechese im Chorgewölbe der Pfarrkirche St. Marein bei Knittelfeld (1463). In: Blätter für Heimatkunde 84 (2010), S. 11-44. ↩
- Handschriftencensus. Eine Bestandsaufnahme der handschriftlichen Überlieferung deutschsprachiger Texte des Mittelalters. Hrsg. v. Rudolf Gamper, Christine Glaßner, Bettina Wagner, Jürgen Wolf und Karin Zimmermann in Zusammenarbeit mit Astrid Breith, Nathanael Busch, Karl Heinz Keller, Klaus Klein und Daniel Könitz. Programmierung und Systemadministration: Tobias Müllerleile. (20.11.2014). ↩
- Das Durchsuchen der Quellentexte des Korpus der mittelalterlichen Kochrezepttexte kann aber über die lemmatisierten Texte der MHDBDBD geschehen, in die alle Kochrezepttextsammlungen des PPM/ MPS eingespeist worden sind. ↩